Interview with Enrico Zimuel, Tech Lead & Principal Software Engineer at Elastic, speaker at the upcoming Bucharest Tech Week, 2024 Edition

Enrico Zimuel is a software developer since 1996, specialized in web technologies and secure software. Open source contributor. TEDx and international speaker
Overview of Retrieval-Augmented Generation (RAG) and its significance in the field of AI
Retrieval-Augmented Generation (RAG) is a technique that extends the capabilities of a Large Language Model without changing the model, eg. fine-tuning. The knowledge of an LLM is augmented using an external vector database that contains some (private) documents. Using a RAG system you can query the database in natural language. The answer is generated using an LLM but the knowledge is retrieved from the documents stored in the database. Typically the knowledge is passed to the LLM using a special prompt technique, called in-context learning. This prompt looks as follows:
I mentioned that we need to use a vector database but what exactly is that? A vector database, like Elasticsearch, stores information using a mathematical representation known as a vector.
A vector is a set of numbers representing the “semantic meaning” of a sentence. The operation to convert a text into a vector is called embedding. This operation is typically executed using a deep neural network that has been trained with many documents. This deep network is able to map a sentence in a multidimensional space, aggregating similar concepts. In Figure 1 is reported an example of a 3 dimensional space with all the words aggregated using a deep network.
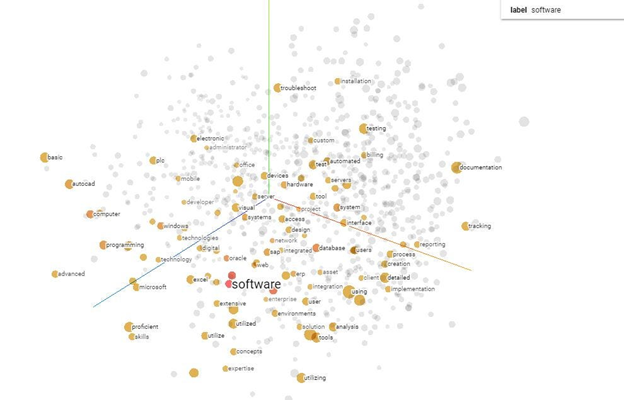
Figure 1: example of 3d space around the “software” concept
In this diagram we notice that words about “software” are close to each other, we can read microsoft, excel, oracle, implementation, etc, all words connected in a semantic way to software.
The size of a vector, called dimension, is typically much bigger than 3, for instance the model text-embedding-ada-002 of OpenAI uses vectors with 1536 dimensions.
To be able to capture all the semantic of the sentences the documents are splitted into chunks. A chunk is typically a part of a document with a variable size depending on the use case, eg. 1024. The embedding is applied for each chunk and stored in the database. When we search using a question this is converted into a vector that is compared with all the neighboring chunks stored in the database (a typical algorithm used is kNN). The similarity between two vectors is expressed using the distance between them. We can define the distance using different formulas: the euclidean distance, the angle or the cosine between the vectors, etc. The search algorithm can be very fast since these mathematical operations are not complicated and they can be also parallelized.
To recap, in a RAG architecture we use a vector database to store the documents representing the knowledge that we want to add to the LLM. We do not perform any fine-tuning operation to the LLM, we pass each time the context for generating the answer in a prompt, using an in-context learning technique. The concept of Retrieval-Augmented Generation (RAG) is gaining significant popularity, and it is now utilized by the majority of contemporary question-and-answer AI systems.
What inspired the development of Langchain, and how does it facilitate the creation of applications for LLMs?
Langchain is an open source framework, developed originally in Python, to address the complexity and the challenges associated with building applications powered by large language models (LLMs). The development was inspired by the need for a structured framework that could simplify the integration, management, and deployment of LLMs in various applications. After Python the community of LangChain ported the code in TypeScript, with the Langchainjs project. For instance, I contributed to this project developing the vectorstore adapter for Elasticsearch.
Using Langchain you can implement many different projects around the usage of a LLM. For instance, you can build a chat-bot assistant that is able to take an order from a customer in natural language. You can implement a RAG system for talking with your private data. You can build a question and answer system for customer service based on the past conversations with the customers, etc.
What are the main advantages of using RAG compared to traditional methods of querying databases?
With a RAG system you can search into a database using natural language and have the response also in natural language. In the traditional databases you typically search using keywords and the result is a list of documents. Using a RAG the retrieval is performed using semantic search that means we can search for the meaning of a sentence instead of the frequency of a keyword. RAG is definitely a disruptive technology compared with the traditional search applications.
How does RAG address privacy concerns when querying sensitive or private datasets?
In the RAG architecture the private datasets are stored in the database and they are not part of the LLM. If you have sensitive data in the database you can decide to remove it when you retrieve the chunk of information that will be used to generate the answer. You can filter the in-context learning part of the prompt at runtime and this is a big advantage. For instance, you can apply data anonymization to remove sensitive information such as email addresses, telephone numbers, etc.
What are the potential limitations or challenges associated with implementing RAG in practical applications?
There are many challenges in implementing an efficient RAG system. The most important is the retrieval part of the semantic search used by the vector database. If the semantic search is not able to retrieve the chunks of the documents that contain the answer the LLM will not be able to generate a proper response. It is important to choose a vector database that can offer different strategies like aggregation, filtering and advanced features like Reciprocal Rank Fusion (RRF) that can boost the quality of the semantic search.
One limitation of the RAG architecture is the fact that it can answer questions using only a subset of documents. Typically the number of chunks that you can retrieve is limited by the maximum prompt size of the LLM (eg. 16k). If the answer of a question needs more documents the RAG will not be able to generate a response. For instance, a question that involves the total number of the documents or filtering the dataset will need a more advanced RAG architecture. You need to apply different techniques like RRF and the usage of external agents that can translate the request into an action, like a SQL statement to elaborate the answer using a traditional database. This last part is still experimental.
How do you see the future evolution of RAG and its potential impact on AI-driven applications?
I think we just started to explore the potential of the RAG architecture and since it applies to all the search use cases we will see a big impact in all the business. The evolution of RAG models represents a significant frontier in AI, with the potential to transform how information is leveraged across numerous industries. Their continued development and integration into AI-driven applications promise to make AI tools more powerful, accurate, and contextually aware, thus enabling more effective decision-making and automation. The RAG architecture will radically change the way we search for information and the natural language will become the standard interface in any software application of the future.
Lastly, what advice would you give to developers or organizations looking to explore and adopt RAG and Langchain in their projects?
My advice is to try as soon as possible to play with this technology. As developers, we need to be prepared for this change that will be significant. There are many resources and articles available online to start with. There are also many open source libraries available in many different languages. Langchain is one the most popular for Python and Javascript but there are many others like LlamaIndex, Semantic Kernel, Haystack, DSPy. Moreover, if you want to execute a LLM on your computer, I suggest using the Ollama project.








